NeMo Guardrails, Guardrails AI, and Llama Guard 3 are not competitors, they are three abstractions for three jobs. NeMo (NVIDIA, Apache 2.0) gives you programmable dialog rails in the Colang DSL across five pipeline stages at under 50ms per check on GPU, best for controlling conversation flow. Guardrails AI is a Python validator architecture with a 50+ validator Hub at 50-200ms per validation, best for enforcing structured output. Llama Guard 3 is an open-weight safety classifier returning safe/unsafe plus category codes at roughly one-third the false-positive rate of GPT-4 on Meta's benchmark. The production answer is rarely one tool: the common stack runs LLM Guard as a fast first-layer scanner, NeMo for dialog control, and Guardrails AI for output enforcement. Pick by what you are guarding (flow, format, or content), not by GitHub stars.
A safety classifier that refuses one in three legitimate requests is not a guardrail, it is an outage with extra steps. That is the trap most teams walk into when they bolt AI guardrails onto a production LLM: they wire in a moderator, watch the attack-block numbers look great in a demo, and only later discover the false-positive tax that quietly drives real users away. Llama Guard 3 exists in large part because of this, posting roughly one-third the false-positive rate of GPT-4 used as a moderator on Meta's own benchmark. The lesson generalizes. The guardrail question is never just "does it block bad stuff," it is "does it block bad stuff without breaking good stuff, fast enough to stay inside my latency SLA."
The confusion in this space starts with the names. NeMo Guardrails, Guardrails AI, and Llama Guard sound like three brands of the same product, so teams evaluate them as interchangeable and pick by GitHub stars. They are not interchangeable. They are three different abstractions for three different jobs: programmable dialog rails that steer conversation flow, output validators that enforce structure and policy, and a classifier model that labels content safe or unsafe. Picking one and assuming it covers the others is how you ship an assistant that validates its JSON perfectly while happily walking off-topic into a jailbreak.
This post is the decision framework we use to scope LLM safety layers. We will break down what each tool actually is, the latency-per-check and false-positive reality, the self-host posture that makes this particular set of tools dominate regulated deployments, and the stacked architecture that nearly every serious production system converges on. The short version: stop asking which guardrail is best and start asking what you are guarding (flow, format, or content), because the answer is usually all three, in that order.
01 · Three Different Abstractions, Not Three Competitors
Before any benchmark, internalize what layer each tool operates at, because the layer determines what it can and cannot protect.
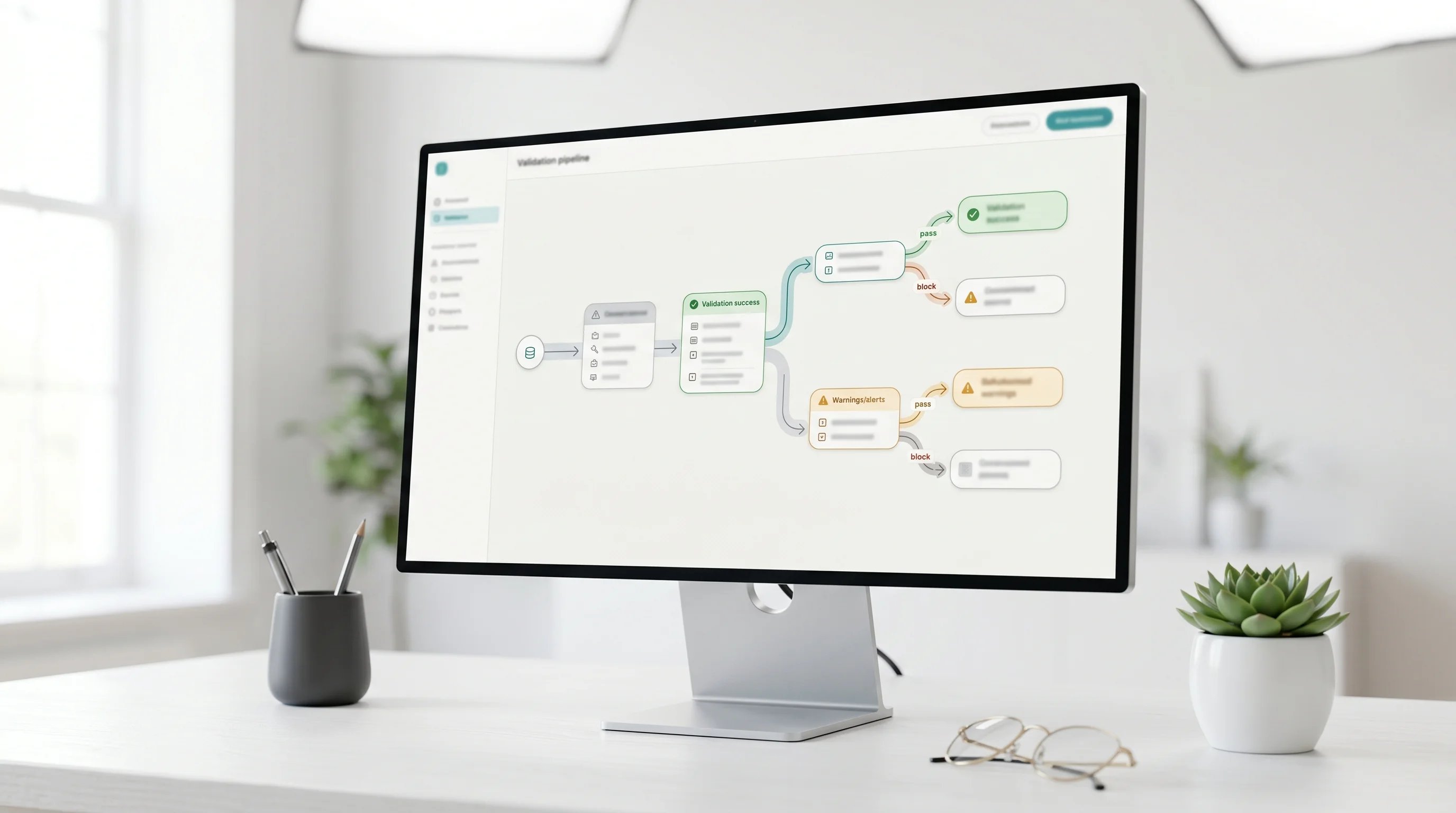
NeMo Guardrails controls dialog flow. Built by NVIDIA and licensed Apache 2.0, it introduces a small domain-specific language called Colang (now Colang 2.0) where you define rails: rules that fire across five pipeline stages, input rails, dialog rails, retrieval rails, execution rails, and output rails. A rail can refuse off-topic requests, force the assistant down a scripted flow, block a tool call, or fact-check a retrieved chunk before it reaches generation. The mental model is a programmable conversation guard sitting around the whole interaction loop, not a single filter. On GPU it runs under 50ms per check, which is why NVIDIA can pitch it for real-time voice and chat. What it is not is a JSON validator or a content classifier. It governs what the assistant is allowed to discuss and do.
Guardrails AI enforces output structure and policy. This is a Python validator architecture: you wrap a model call and attach validators to its input or output. The Guardrails Hub ships 50+ prebuilt validators (PII detection, toxic language, competitor mentions, valid JSON, SQL safety, profanity, regex match, and more), and you can write your own. Each validator inspects the text and either passes it, fixes it, or raises. Latency runs 50-200ms per validation depending on whether the validator is pure regex or calls a model. The mental model here is a contract on the output: the response must be valid JSON, must contain no PII, must not mention a competitor. It does not steer the conversation; it polices the result.
Llama Guard 3 classifies content. This is an open-weight safety model from Meta, fine-tuned to take a prompt or a response and return a structured verdict: safe or unsafe, and when unsafe, a category code (S1 through S13 in the MLCommons taxonomy, covering violent crimes, hate, self-harm, and so on). It is not a framework you write rules in, it is a model you run an inference pass against. You can point it at the user's input, the assistant's output, or both. Because it is open-weight, you self-host it for zero per-call cost and full data residency. The mental model is a dedicated bouncer that reads each message and stamps it safe or unsafe with a reason code.
LLM Guard rounds out the stack as the fast first layer. Open source, it runs a battery of input and output scanners (prompt injection detection, jailbreak strings, secrets, token limits, banned topics, anonymization) at the front of the pipeline so cheap, obvious attacks die before any expensive model runs. It overlaps Guardrails AI in places but is positioned as the lightweight gate, not the policy engine.
These four are not on a collision course toward one product. They are layers. The architecture that wins composes them rather than choosing among them.
02 · NeMo Guardrails: Programmable Dialog Rails in Colang
NeMo Guardrails is the right tool when your safety requirement is about the flow of the conversation, not just the shape of a single response. Think of an assistant that must stay strictly inside a customer-support domain, must never give medical or legal advice, must invoke a specific tool before answering certain questions, and must run a fact-check rail over retrieved context before generating. That is dialog logic, and Colang is built for it.
The five-stage pipeline is the feature that distinguishes NeMo from a flat filter. An input rail can reject a request before the LLM ever sees it. A dialog rail can match the user's intent against canonical flows and route accordingly. A retrieval rail can screen RAG chunks. An execution rail can gate tool calls. An output rail can refuse or rewrite the final response. You are programming guard logic at every hop, which is exactly what agentic systems need, because the dangerous moments in an agent are the tool calls and the retrieval steps, not just the final text.
The cost is the learning curve. Colang is a real DSL with its own concepts (flows, canonical forms, subflows), and teams underestimate the ramp. The payoff is precision: you can express policies in NeMo that would be brittle as a pile of regex validators. The under-50ms-per-check GPU latency makes it viable for real-time, but that figure assumes GPU inference for the embedding and intent-matching steps. On CPU the picture changes, so size your hardware against the latency budget before committing. For agent systems specifically, the dialog and execution rails pair naturally with the layered escalation logic in our guide on AI fallback patterns across models, rules, and human escalation, since a blocked rail needs somewhere to send the user.
03 · Guardrails AI: The Validator Hub for Structured Output
Where NeMo governs the conversation, Guardrails AI governs the artifact. If your failure mode is "the model returned malformed JSON," "the response leaked a customer email," or "the summary mentioned a competitor by name," this is the layer that catches it.
The Hub is the differentiator. Instead of hand-writing every check, you compose from 50+ validators and only build custom ones for genuinely domain-specific rules. A typical guard might chain a JSON-schema validator, a PII detector, a toxicity check, and a profanity filter, each running in sequence over the output. When a validator fails, you choose the behavior: raise an exception, filter the offending span, or trigger a re-ask where the model is prompted to fix its own output.
The 50-200ms-per-validation range is the honest cost, and it stacks. Five validators on a response can add a meaningful chunk of your latency budget, and model-based validators (toxicity, PII via NER) sit at the slow end of that range. The mitigation is to order validators cheap-first and short-circuit: run the regex and schema checks before the model-based ones, so a malformed response fails on the cheap check and never pays for the expensive one. Validation discipline here overlaps heavily with the broader practice of securing AI systems that handle sensitive data, where PII redaction in the output path is non-negotiable.
04 · Llama Guard 3 vs LLM Guard: Classifier vs Scanner
These two are the most often confused, because both sound like content filters. The distinction is depth versus speed.
Llama Guard 3 is a model. You spend an inference pass and get back a nuanced, category-coded verdict that understands context, intent, and the difference between discussing self-harm and encouraging it. The roughly one-third false-positive rate relative to GPT-4 on Meta's benchmark is its headline advantage: it blocks the genuinely unsafe without nuking the merely sensitive. It also returns structured output (safe/unsafe plus a category) instead of prose you have to parse, which makes it trivial to wire into routing logic. The cost is an inference pass per check, so on very high volume you place it carefully rather than on every message.
LLM Guard is a scanner battery. Its job is to be the cheap front gate: catch the obvious prompt injection strings, jailbreak templates, leaked secrets, and oversized inputs with regex and lightweight models before anything expensive runs. It is fast and broad but shallow; it will not reason about whether a borderline request is actually harmful the way a classifier model can.
The two are complementary, not redundant. LLM Guard fails fast on cheap signals; Llama Guard 3 makes the nuanced content call on traffic that survives. For the specific problem of injection, neither is a silver bullet. The published data is sobering, and our deep dive on protecting AI systems from prompt injection attacks walks through why a scanner catches known patterns but adaptive attacks still get through, which is the whole argument for layering rather than trusting one filter.
05 · Latency, False Positives, and License: The Comparison Table
Here is the side-by-side that actually drives the decision. The numbers are the published and vendor-stated figures as of Q2 2026; confirm against your own hardware, because latency is hardware-dependent and false-positive rates are benchmark-dependent.
A few patterns hold across the table:
| Tool | Abstraction | Latency per check | False positives | License | Self-host | Best for |
|---|---|---|---|---|---|---|
| NeMo Guardrails | Programmable dialog rails | < 50ms on GPU | Policy-dependent | Apache 2.0 | Yes | Conversation flow + tool gating |
| Guardrails AI | Output validators | 50-200ms/validation | Validator-dependent | Open core | Yes | Structured output enforcement |
| Llama Guard 3 | Safety classifier model | Tens-hundreds ms | ~1/3 of GPT-4 (Meta benchmark) | Open weights | Yes | Content classification (in/out) |
| LLM Guard | Input/output scanner | Single-digit to tens ms | Pattern-dependent | Open source | Yes | Fast first-layer screening |
06 · The Stacked Deployment Everyone Converges On
The single most useful thing to internalize is that the production answer is not a tool, it is a pipeline. Across the LLM safety architectures we have reviewed and shipped, the converged pattern looks like this, ordered cheapest-first so the latency budget stays sane:
The ordering is the whole point. Each layer is cheap relative to the cost of the incident it prevents, and running them cheapest-first means the expensive classifier passes only see traffic that already survived the gates. Picture a customer-support assistant that fields a million messages a day: if you run Llama Guard inference on every one of those messages on input and output, you have doubled your inference bill before the actual model runs. Run LLM Guard and NeMo rails first, and the classifier only touches the fraction of traffic that warrants it.
This composition mindset is the same discipline we apply to the rest of the AI security surface. Guardrails sit alongside, not instead of, the controls in our MCP server security hardening checklist, because a guardrailed model that calls an unhardened tool server has just moved the attack surface, not closed it. At Particula Tech, when we scope a safety layer, the first artifact is this pipeline diagram with a latency budget assigned to each stage, because that is what turns "we added guardrails" into "we measured a 4ms front gate, a 40ms dialog rail, and a 120ms output validation, total well inside our 800ms SLA."
07 · Decision Matrix: What Are You Actually Guarding?
Skip the feature checklist. The decision reduces to one question with three answers, and most real systems answer "all three."
A few warnings worth flagging. "We added Guardrails AI" does not mean your conversation is safe, because output validation says nothing about whether the assistant walked into a jailbreak, that is NeMo's job. "Llama Guard blocks unsafe content" does not mean your JSON is valid, that is Guardrails AI's job. "NeMo controls the dialog" does not mean obvious injection strings die cheaply, that is LLM Guard's job. The categories of failure are genuinely orthogonal, which is why the stack exists.
And the honest caveat on all of it: guardrails reduce attack success substantially but do not eliminate it. The published prompt-injection benchmarks show adaptive and composite attacks getting through at meaningful rates even against layered defenses. Treat this stack as defense-in-depth with quantified expectations, measure residual attack success against your own red-team set, and pair it with architectural controls (least-privilege tool scoping, human escalation on high-risk actions). The broader strategic context for where guardrails fit among prompt-injection defense, data protection, and access control lives in our AI Security pillar.
| Your primary risk | Pick | Why |
|---|---|---|
| Assistant goes off-topic, calls wrong tools, ignores policy | NeMo Guardrails | Programmable rails across 5 stages control flow and tool use, < 50ms GPU |
| Output must be valid JSON, PII-free, policy-clean | Guardrails AI | 50+ validator Hub enforces the output contract, compose and short-circuit |
| Need to label content safe/unsafe with categories | Llama Guard 3 | Purpose-built classifier, ~1/3 GPT-4 false positives, structured verdict |
| Cheap fast gate against obvious injection/secrets | LLM Guard | Single-digit-ms scanner, fail fast before expensive layers run |
| Real production system at any meaningful scale | Stack all four | Flow + format + content are different jobs; order cheapest-first |
| Regulated, data must stay in your VPC | This whole stack | All four self-host (Apache 2.0, open weights, open source), no cloud transit |
08 · Recommendation by Scenario
We close every guardrail scoping conversation with concrete starting points. They are imperfect, every workload has wrinkles, but they hold up most often:
The wrong move in every case is shipping one tool and calling it a guardrail. Flow, format, and content are three different jobs, and the systems that get breached or that flood users with false refusals are almost always the ones that picked a single abstraction and assumed it covered the rest. Pick by what you are guarding. Order the layers cheapest-first. Measure your residual risk on real traffic, not a demo.
09 · FAQ
Quick answers to the questions this post tends to raise.



